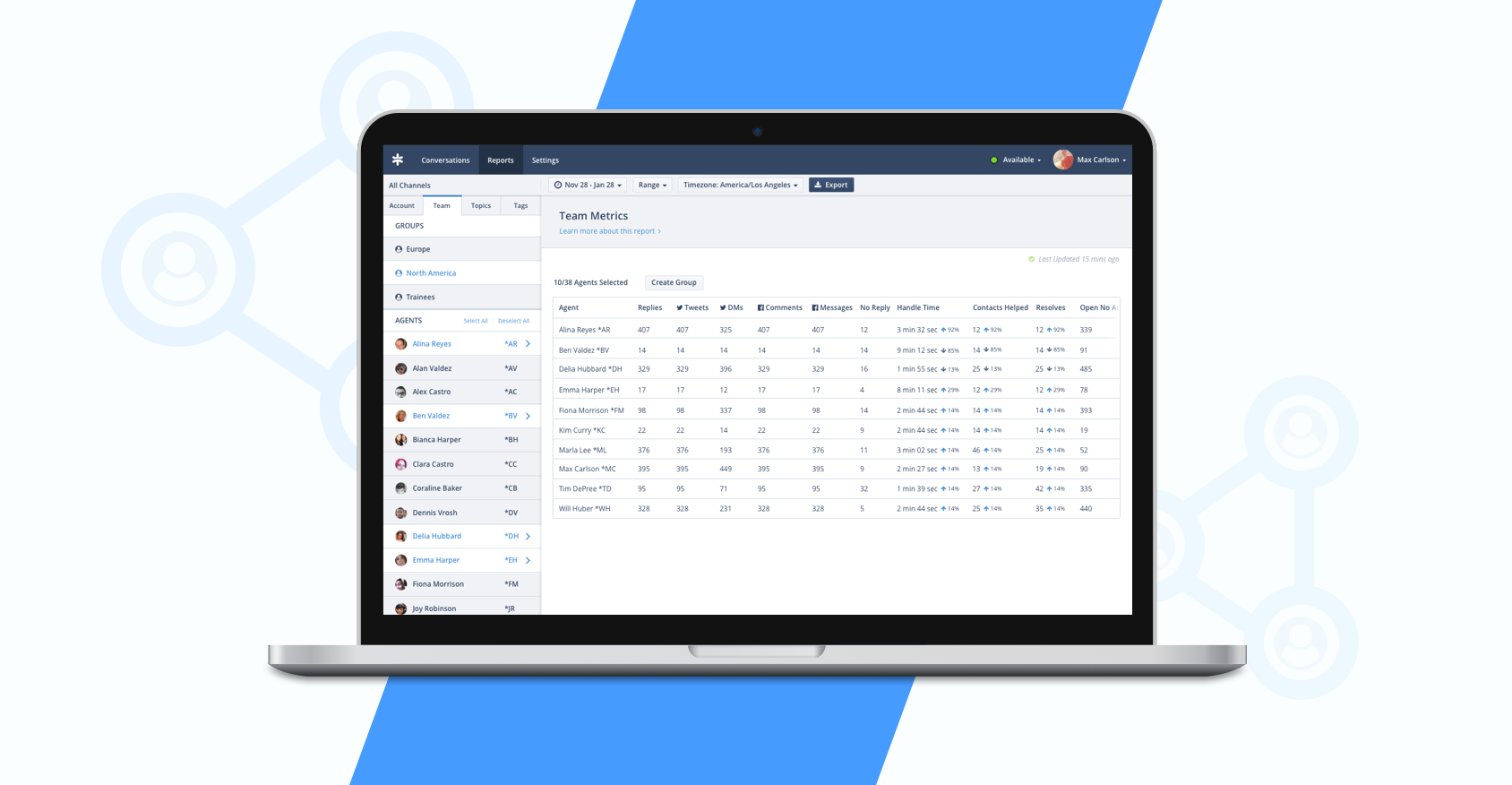
Sparkcentral Groups
Within Sparkcentral's Reporting, analysts distill data relating to message volume, response time, team performance, and more. Data pulled from the Team Report was being used to inform staffing decisions, allowing teams to anticipate busy times in order to appropriately hire and schedule agents.
Problem
When exporting data on a subset of agents, the user had to select each agent one-by-one. While this was never the best experience, it served its purpose well for Sparkcentral's early SMB clients. As Sparkcentral grew, it began to serve teams of hundreds of agents, rendering this selection pattern and the overall Team Report experience unruly. Analysts on these larger teams were spending hours simply selecting agents on which to export data. This process was becoming a huge obstacle to their daily work. There were clear, repeatable actions being performed that demanded a more intelligent solution.
Goal
My goal was to create a new, scalable selection pattern that would reduce what had become an hours-long process down to mere seconds.
Solution
Analysts were often exporting data on the same subsets of agents on a regular basis. We introduced Groups to the Team Report, essentially creating shortcuts to select these subsets of agents. The needs regarding groups varies from organization to organization; they're usually formed around a shared skillset (such as language or domain expertise), work shifts, or team structure. Groups was immediately received very well; analysts were immensely relieved, as the feature freed up significant time in their daily workflows. It allowed them to focus on making meaningful decisions based on data, rather than spending so much time simply retrieving data.
Want to know more?
Information provided here is only a piece of the story. If you'd like to know more about the process, research, and results of the project, please contact me and I'd be happy to share.